
Sentence Line Detection for Improving OCR
This research proposes a method to improve the accuracy of single-line text detection in optical character recognition (OCR). Especially when the text contains many character types and multi-line text with narrow line spacing, such as in Japanese, existing deep learning-based text detection tools often treat multiple lines as a single region and require line segmentation for OCR.
The proposed method is based on CRAFT, an existing text detection model, and adds a deep neural network specialized for line segmentation to detect single lines among multiple lines. Furthermore, we have introduced a post-processing algorithm that uses the output of line segmentation to accurately detect single-line regions even in multi-line text with narrow line spacing.
An overview of the proposed model is shown below.
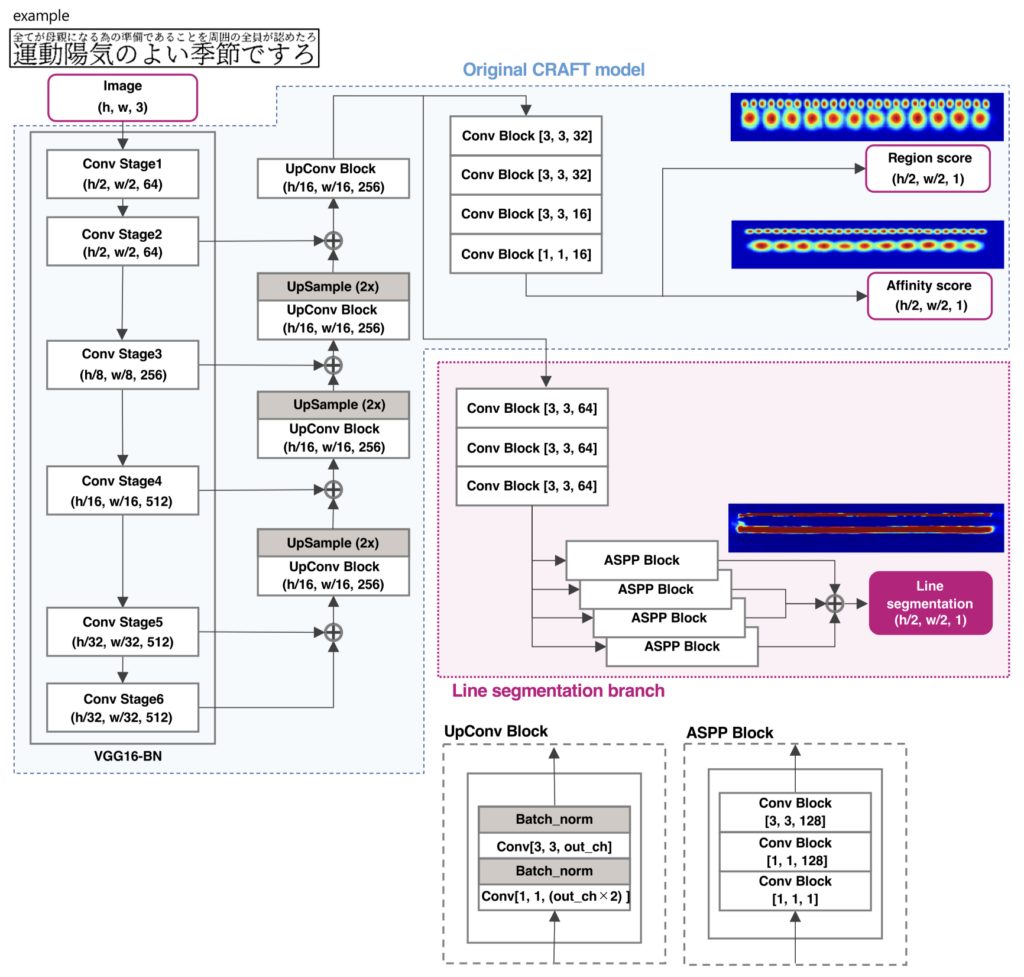
Label data for line segmentation can be automatically generated from character-by-character bounding box information needed for CRAFT training. The procedure for determining single-line text regions using the results of line segmentation and character region detection is as follows.
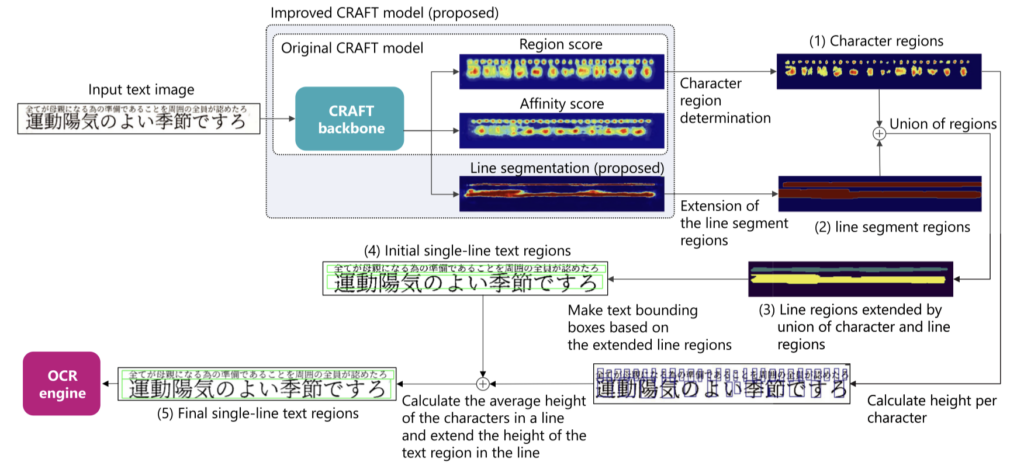
Evaluation experiments using Japanese multi-line text images show that the proposed method outperforms existing methods such as CRAFT, DBNet, and DBNet++ in terms of both single-line detection and OCR accuracy. Even when the line spacing is narrow, the proposed method is able to detect single lines more accurately.
This study shows that adding a line segmentation task to CRAFT enables single-line detection and that post-processing based on character area detection and line segmentation detection can achieve even more accurate single-line text detection. The proposed method was shown to significantly improve the accuracy of character recognition of multi-line text by OCR engines.
- Chee Siang Leow, Hideaki Yajima, Tomoki Kitagawa and Hiromitsu Nishizaki, “Single-line Text Detection in Multi-line Text with Narrow Spacing for Line-based Character Recognition,” IEICE Transaction on Information & Systems, Vol.E106-D, No.12, pp.2097-2106, 2023. DOI:10.1587/transinf.2023EDP7070
文字認識(OCR)精度向上のための文ライン検出
本研究では、光学文字認識(OCR)における単一行テキスト検出の精度向上を目的とした手法を提案しています。特に日本語のように文字種が多く、行間隔の狭い複数行テキストが含まれる場合には、既存の深層学習ベースのテキスト検出ツールでは複数行を1つの領域として扱ってしまうことが多く、OCRのための行分割が必要となります。
提案手法では、既存のテキスト検出モデルであるCRAFTをベースとし、行分割に特化した深層ニューラルネットワークを追加することで、複数行の中から単一行を検出します。さらに、行分割の出力を用いた後処理アルゴリズムを導入し、行間隔の狭い複数行テキストにおいても単一行領域を正確に検出できるようにしました。
日本語の複数行テキスト画像を用いた評価実験では、提案手法がCRAFTやDBNet、DBNet++といった既存手法と比較して、単一行検出精度とOCR精度の両面で優れていることが示されました。行間隔が狭い場合でも、提案手法は単一行をより正確に検出できています。
本研究により、行分割タスクをCRAFTに追加することで単一行検出が可能となり、文字領域検出と行分割検出に基づく後処理によってさらに正確な単一行テキスト検出が実現できることが明らかになりました。 提案手法を用いることで、OCRエンジンによる複数行テキストの文字認識精度が大幅に改善されることが示されました。