低遅延なリアルタイム音声認識システムの開発
Development of Real-time Automatic Speech Recognition with Low-latency
Googleを始めとして音声認識サービスが実用化されていますが,商用(あるいは無償の)サービスでは,自由にカスタマイズができない,インターネット接続が必要などといった制約があります。そこで,高精度でモデル等をカスタマイズできる低遅延(しゃべり終わったらすぐに結果がでてくる)のリアルタイム音声認識システムの研究開発を行っています。
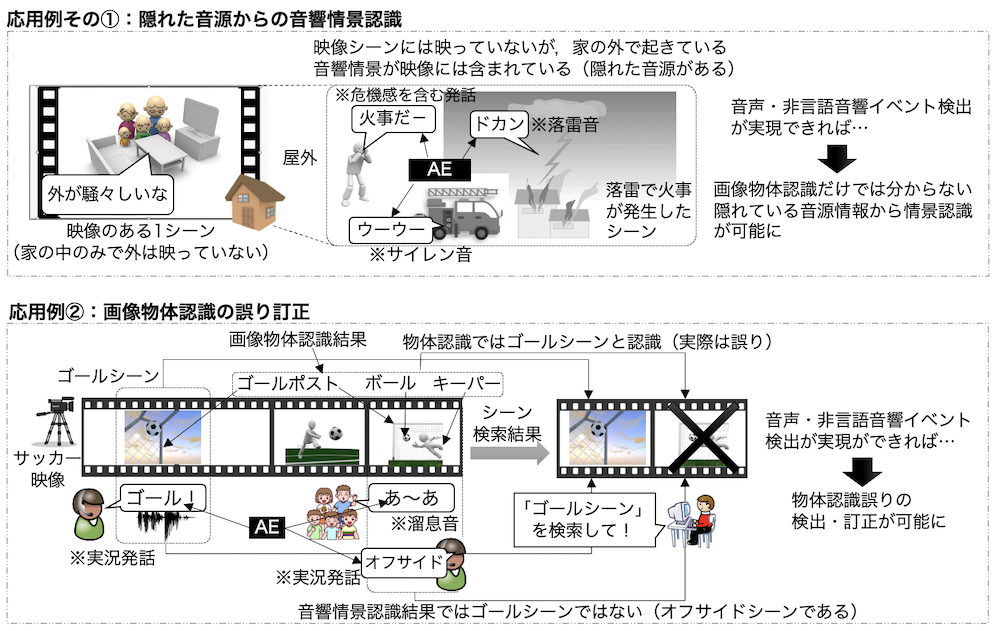
本研究室では,下図のように,音声認識システムKaldiをベースにした音声認識システムを開発し公開しています。オンライン会議システムや,Web配信されている動画などの音声をリアルタイムに認識し,表示できます。
Although Google and other speech-to-text services have been commercialized, commercial (or free) services have limitations such as lack of freedom in customization and the need for Internet connection.
Therefore, we are researching and developing a low-latency real-time automatic speech recognition (ASR) system with high accuracy and customizable models (the results are displayed as soon as a user finishes speaking). As shown in the figure below, we have developed and released an ASR system based on the Kaldi speech recognition system. The system is capable of recognizing and displaying audio from online conference systems and webcasting videos in real time.
- 発表動画 / Presentation Video Youtube (GCCE2020で発表) 発表論文 / Paper IEEE Xplore
Python言語による音声認識システムの開発
Development of ASR system with Python Programming Language
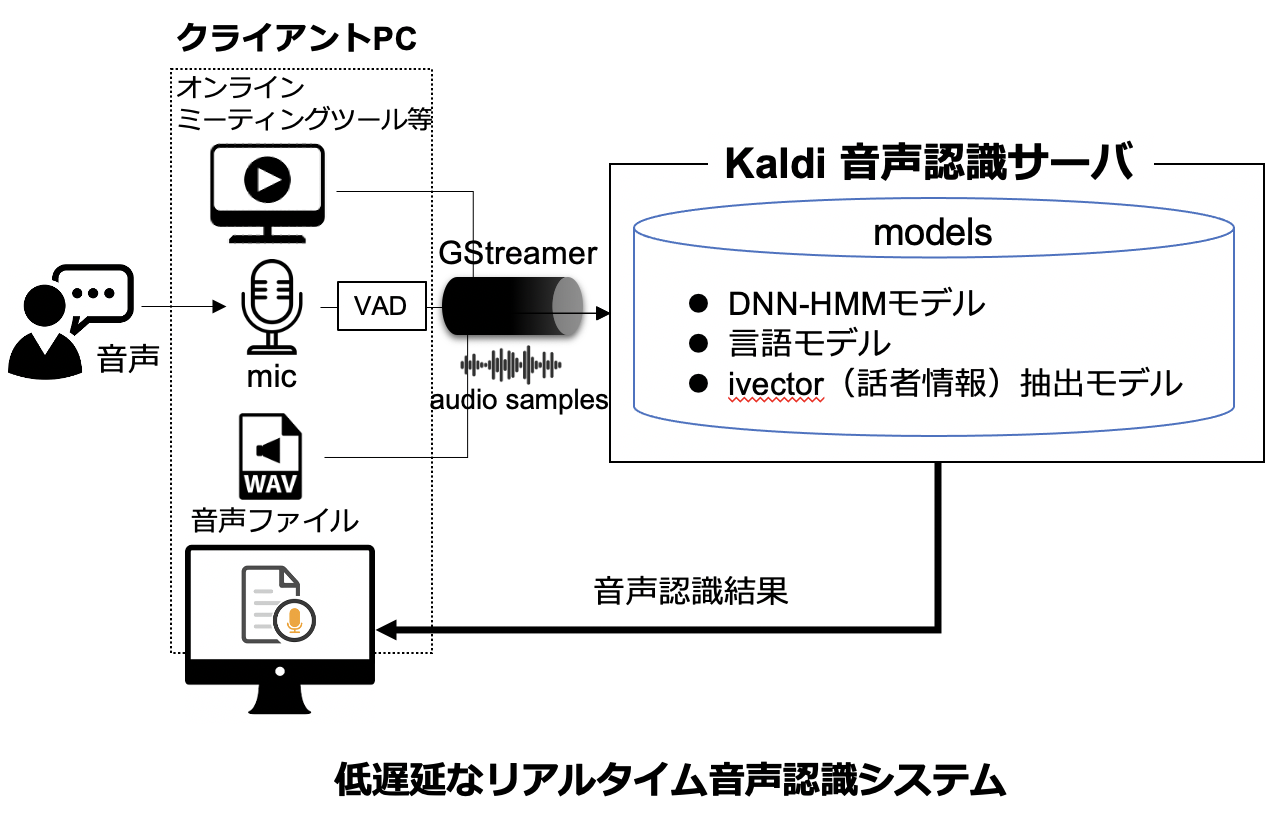
音声認識システムKaldiをベースとした完全にPython言語で動作する音声認識システム “ExKaldi” および,ストリーミング音声認識システム “ExKaldi-RT” を開発しています。Kaldiで用いる音響モデルを,ディープラーニングのフレームワークである,TensorFlowやPyTorchで訓練できるツールを提供しています。
ExKaldiとExKaldi-RTは,それぞれGithubで公開しています。
We are developing an ASR system “ExKaldi” and a streaming ASR system “ExKaldi-RT”, both of which are based on the Kaldi ASR toolkit and run completely in Python. We provide tools to train the acoustic models used in ExKaldi with TensorFlow and PyTorch, frameworks for deep learning. ExKaldi and ExKaldi-RT are available on Github.
- ExKaldi: https://github.com/wangyu09/exkaldi 発表動画 / Presentation movie Youtube 発表論文 / paper IEEE Xplore
- ExKaldi-RT: https://github.com/wangyu09/exkaldi-rt 論文 / paper arXiv
環境音認識技術の研究